Siléane Dataset
Siléane Dataset for Object Detection and Pose Estimation
This dataset consists in a total of 2601 independent scenes depicting various numbers of object instances in bulk, fully annotated. It is primarily designed for the evaluation of object detection and pose estimation methods based on depth or RGBD data, and consists of both synthetic and real data.
Synthetic data is made of scenes representing the inside of a bin, in which a random number of object instances have been dropped (in some scenes, there are no visible instances at all).
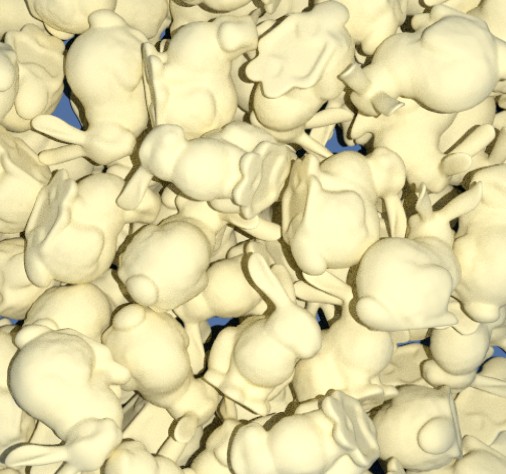


Real data consists similarly in scenes of various numbers of object instances (between 0 and 11) lying on a surface at various distances from the camera. We considered two different background surfaces: a planar one (markers flat, 308 scenes), representative of the typical bottom of a bin; and a bumpy surface (markers bump, 325 scenes), increasing the variability of poses and producing a pose distribution more consistent with the scenario of many instances piled up. In order to validate the use of synthetic data for evaluation, we also propose a synthetic dataset (markers flat simulation) reproducing real scenes that enables pairwise comparison.




Lastly, an additional dataset of 46 scenes (markers clutter) targets the problem of object detection and pose estimation in a cluttered environment.
Dataset description
Archive description
- rgb: RGB or intensity image.
- depth: depth image from the same viewpoint as the RGB data, encoded as a 16bit unsigned PNG image.
- depth_gt: ideal depth image, if available.
- segmentation: segmentation of the various instances of the scene.
- gt: ground truth annotations for each scene.
- mesh.ply: 3D triangular mesh model of the object.
- poseutils.json: description of geometric properties of the object used by evaluation scripts, notably its symmetry group.
- camera_params.txt: camera parameters considered.
File format
Ground truth
Ground truth pose annotations for a dataset are provided in JSON format for each scene such as follows:
[{"R": [[-0.71494568144, -0.29784533696000004, -0.63256695358],
[0.65633897998, -0.5977253336480001, -0.46037342646400004],
[-0.24098120024000003, -0.7443202964360001, 0.622828612352]],
"segmentation_id": 65535,
"occlusion_rate": 0.10165770117466244,
"t": [-0.133393, -0.043768, 0.221253]},
{"R": [[-0.160880605701, 0.10835646816000002, 0.9810084635799999],
[0.40743837264000005, -0.8980182051009999, 0.16600775556000003],
[0.8989508898199999, 0.42640764324, 0.10032506454899998]],
"segmentation_id": 64599,
"occlusion_rate": 0.09766150740242263, "t": [-0.132352, 0.177468, 0.233303]}]
In this example, the scene contains two object instances. Their poses are described by a rotation matrix \(R\) and a translation vector \(t\) in such a way that a point \(x\) expressed in the object frame can be expressed in the absolute coordinates system by \(R x + t\). Occlusion rate of each instance is also provided (defined as the fraction of the object's silhouette visible in the depth data), as well as the color in the 16bit segmentation image.
Camera parameters
Camera parameters are described within a text file of the following format:
width 506
height 474
fu 1152.31
fv 1152.31
cu 139.459
cv 237.001
clip_start 0.87599
clip_end 1.70602
# Location of the camera, expressed by a 3D translation vector.
location -0.1 0 1.5
# Orientation of the camera, expressed by an unit quaternion (w x y z).
rotation 8.72098e-008 1 -4.57187e-009 -9.94784e-010
The coordinates \((x, y, z)\) of in camera frame can be computed from the value of the depth image \(D(u, v) \in [0, 1] \) at a pixel \((u, v)\) as follows: \[ \left\lbrace \begin{align} z &= \mathrm{clip\_start} + (\mathrm{clip\_end} - \mathrm{clip\_start})D(u, v) \\ x &= \cfrac{z}{f_u} (u - c_u) \\ y &= \cfrac{z}{f_v} (v - c_v). \end{align}\right. \] White pixels in the depth image represent points which have not been reconstructed.
Symmetry group
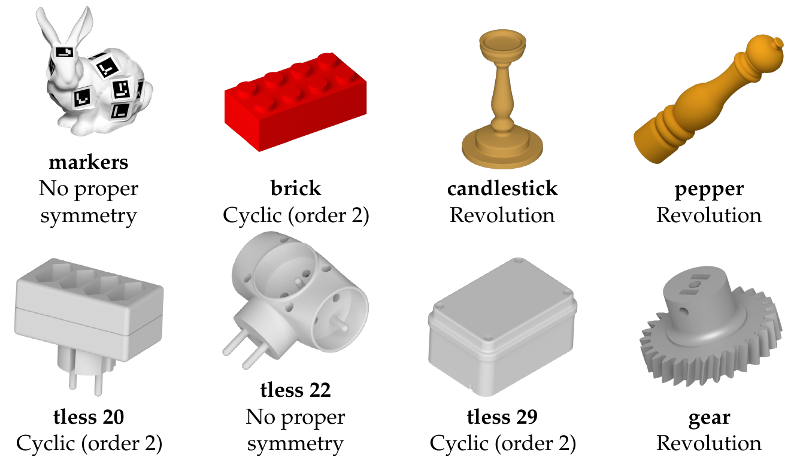
The proposed evaluation methodology is based on the symmetry group of the object considered .The symmetry group depends on what static configurations of the object we wish to distinguish, and this choice is not necessarily obvious. For example, the gear object could be considered as an object with a cyclic symmetry of order 2 -- i.e. an invariance under rotation of 1/2 turn about a given axis -- a cyclic symmetry of order its number of teeth, or a revolution symmetry depending on the level of details considered. We considered this latter option in our experiments, and synthesize the choices of symmetry classes we made below:
3D models
3D models of the tless objects used in this dataset are taken from the T-LESS dataset of T. Hodaň et al. The bunny and markers models are modified versions of original Stanford bunny from the Stanford University Computer Graphics Laboratory. Other models have been downloaded from online archives in 2016-2017: "Pepper & Salt Mill Peugeot" by Ramenta (3D Warehouse), "Samdan 2" by Metin N. (3D Warehouse).
Download
The data can be downloaded as a set of 7zip archives here.
Additionally, we provide some evaluation tools on GitHub to ease the use of this dataset: GitHub link.
Please cite the following paper if you use this dataset:
Romain Brégier, Frédéric Devernay, Laetitia Leyrit and James L. Crowley, "Symmetry Aware Evaluation of 3D Object Detection and Pose Estimation in Scenes of Many Parts in Bulk", in The IEEE International Conference on Computer Vision (ICCV), 2017, pp. 2209-2218.
(paper,
supplementary material ,
poster).
@InProceedings{bregier2017iccv,
author = {Br{\'e}gier, Romain and Devernay, Fr{\'e}d{\'e}ric and Leyrit, Laetitia and Crowley, James L.},
title = {Symmetry Aware Evaluation of 3D Object Detection and Pose Estimation in Scenes of Many Parts in Bulk},
booktitle = {The IEEE International Conference on Computer Vision (ICCV)},
month = {Oct},
year = {2017}
}
For any question or remark, contact information can be found here.
The Siléane Dataset is licensed under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
